APEX Data Parser – How to Parse XLSX and CSV?
PARSE Function
This is the main parser function. It allows to parse XML, XLSX, CSV or JSON files and returns a generic table of the following structure:
Structure of parser return
LINE_NUMBER, COL001, COL002, COL003, COL004 … COL300
We have line_number and 300 other columns, having said that we can read 300 columns from the above four file formats.
Parser Function parameters.
FUNCTION parse (p_content IN BLOB,
p_file_name IN VARCHAR2 DEFAULT NULL,
p_file_type IN t_file_type DEFAULT NULL,
p_file_profile IN CLOB DEFAULT NULL,
p_detect_data_types IN VARCHAR2 DEFAULT 'Y',
p_decimal_char IN VARCHAR2 DEFAULT NULL,
p_xlsx_sheet_name IN VARCHAR2 DEFAULT NULL,
p_row_selector IN VARCHAR2 DEFAULT NULL,
p_csv_row_delimiter IN VARCHAR2 DEFAULT lf,
p_csv_col_delimiter IN VARCHAR2 DEFAULT NULL,
p_csv_enclosed IN VARCHAR2 DEFAULT '"',
p_skip_rows IN PLS_INTEGER DEFAULT 0,
p_add_headers_row IN VARCHAR2 DEFAULT 'N',
p_file_charset IN VARCHAR2 DEFAULT 'AL32UTF8',
p_max_rows IN NUMBER DEFAULT NULL,
p_return_rows IN NUMBER DEFAULT NULL,
p_store_profile_to_collection IN VARCHAR2 DEFAULT NULL)
RETURN wwv_flow_t_parser_table PIPELINED;
| Parameter | Description |
|---|---|
| P_CONTENT | The file content to be parsed as a BLOB |
| P_FILE_NAME | The name of the file; only used to derive the file type. Either P_FILE_NAME, P_FILE_TYPE or P_FILE_PROFILE |
| P_FILE_TYPE | The type of the file to be parsed. Use this to explicitly pass the file type in. Either P_FILE_NAME, P_FILE_TYPE or P_FILE_PROFILE must be passed in. |
| P_FILE_PROFILE | File profile to be used for parsing. The file profile might have been computed in a previous PARSE() invocation. If passed in again, the function will skip some profile detection logic and use the passed in profile – in order to improve performance. |
| P_DETECT_DATA_TYPES | Whether to detect data types (NUMBER, DATE, TIMESTAMP) during parsing. If set to ‘Y’, the function will compute the file profile and also add data type information to it. If set to ‘N’, no data types will be detected and all columns will be VARCHAR2. Default is ‘Y’. |
| P_DECIMAL_CHAR | Use this decimal character when trying to detect NUMBER data types. If not specified,the procedure will auto-detect the decimal character. |
| P_XLSX_SHEET_NAME | For XLSX workbooks. The name of the worksheet to parse. If omitted, the function uses the first worksheet found. |
| P_ROW_SELECTOR | For JSON and XML files. Pointer to the array / list of rows within the JSON or XML file. If omitted, the function will: |
| For XML files: Use “//” (first tag under the root tag) as the row selector. | |
| For JSON files: Look for a JSON array and use the first array found. | |
| For XML files: Use “//” (first tag under the root tag) as the row selector. | |
| For JSON files: Look for a JSON array and use the first array found. |
Examples:
CREATE TABLE loader_files
(
id NUMBER,
file_content BLOB
);
How to parse XLSX?
Insert excel file, Let’s take a workbook with two worksheets.
Worksheet 1
| Line No | ITEMS | Store |
|---|---|---|
| 1 | Apple | New Delhi |
| 2 | Shampoo | Noida |
| 3 | Milk | Gurugram |
| 4 | Veggies | Pune |
Worksheet 2
| Item | Qty |
|---|---|
| 10001 | Ab1 |
| 10002 | Ab2 |
| 10003 | Ab3 |
| 10004 | Ab4 |
| 10005 | Ab5 |
| 10006 | Ab6 |
| 10007 | Ab7 |
| 10008 | Ab8 |
| 10009 | Ab9 |
| 10010 | Ab10 |
| 10011 | Ab11 |
| 10012 | Ab12 |
| 10013 | Ab13 |
| 10014 | Ab14 |
| 10015 | Ab15 |
| 10016 | Ab16 |
| 10017 | Ab17 |
| 10018 | Ab18 |
| 10019 | Ab19 |
| 10020 | Ab20 |
| 10021 | Ab21 |
SELECT line_number,
col001,
col002,
col003
FROM TABLE (apex_data_parser.parse (p_content => (SELECT file_content
FROM loader_files
WHERE id = 1),
p_file_name => 'data.xlsx',
p_xlsx_sheet_name => 'sheet1.xml',
p_skip_rows => 0));
Output
| LINE_NUMBER | COL001 | COL002 | COL003 |
|---|---|---|---|
| 1 | Line No | ITEMS | Store |
| 2 | 1 | Apple | New Delhi |
| 3 | 2 | Shampoo | Noida |
| 4 | 3 | Milk | Gurugram |
| 5 | 4 | Veggies | Pune |
To skip the headers in the file, set p_skip_rows to 1.
SELECT line_number,
col001,
col002,
col003
FROM TABLE (apex_data_parser.parse (p_content => (SELECT file_content
FROM loader_files
WHERE id = 1),
p_file_name => 'data.xlsx',
p_xlsx_sheet_name => 'sheet1.xml',
p_skip_rows => 1));
| LINE_NUMBER | COL001 | COL002 | COL003 |
|---|---|---|---|
| 1 | 1 | Apple | New Delhi |
| 2 | 2 | Shampoo | Noida |
| 3 | 3 | Milk | Gurugram |
| 4 | 4 | Veggies | Pune |
Data from the Second Sheet.
SELECT line_number,
col001,
col002,
col003
FROM TABLE (apex_data_parser.parse (p_content => (SELECT file_content
FROM loader_files
WHERE id = 1),
p_file_name => 'data.xlsx',
p_xlsx_sheet_name => 'sheet2.xml',
p_skip_rows => 1));
Output
| LINE_NUMBER | COL001 | COL002 | COL003 |
|---|---|---|---|
| 1 | Item | Qty | |
| 2 | 10001 | Ab1 | |
| 3 | 10002 | Ab2 | |
| . | . | . | . |
| . | . | . | . |
| 20 | 10019 | Ab19 | |
| 21 | 10020 | Ab20 | |
| 22 | 10021 | Ab21 |
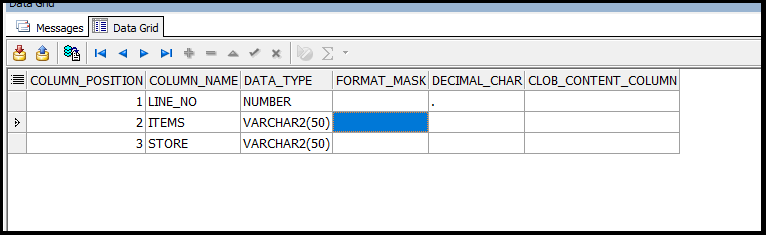
How to get the Column List from Worksheet?
SELECT *
FROM TABLE (
apex_data_parser.get_columns (apex_data_parser.discover (
p_content => (SELECT file_content
FROM loader_files
WHERE id = 1),
p_file_name => 'large.xlsx')));
How to get the list of worksheets?
SELECT *
FROM TABLE (apex_data_parser.get_xlsx_worksheets (
p_content => (SELECT file_content
FROM loader_files
WHERE id = 1)));
| SHEET_SEQUENCE | SHEET_DISPLAY_NAME | SHEET_FILE_NAME | SHEET_PATH |
|---|---|---|---|
| 1 | A | sheet1.xml | worksheets/sheet1.xml |
| 2 | B | sheet2.xml | worksheets/sheet2.xml |
How to parse CSV files?
Files data
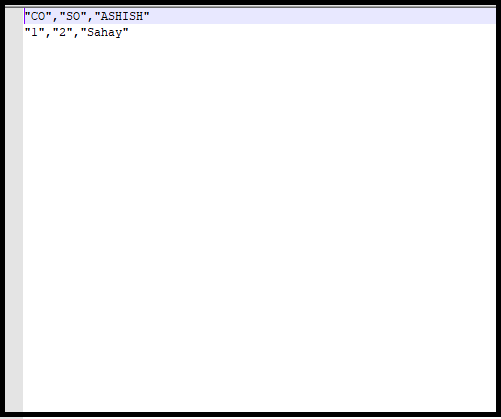
SELECT *
FROM TABLE (apex_data_parser.parse (p_content => (SELECT file_content
FROM loader_files
WHERE id = 2),
p_file_name => 'data.csv'));
| LINE_NUMBER | COL001 | COL002 | COL003 |
|---|---|---|---|
| 1 | CO | SO | ASHISH |
| 2 | 1 | 2 | Sahay |